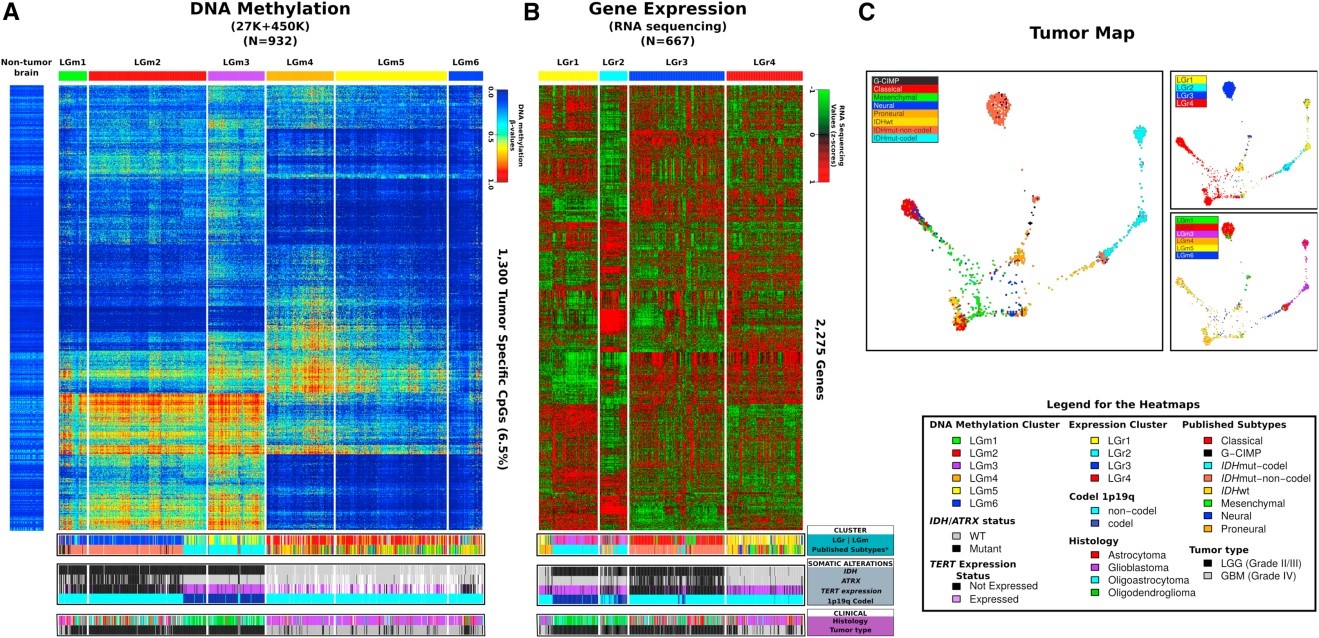
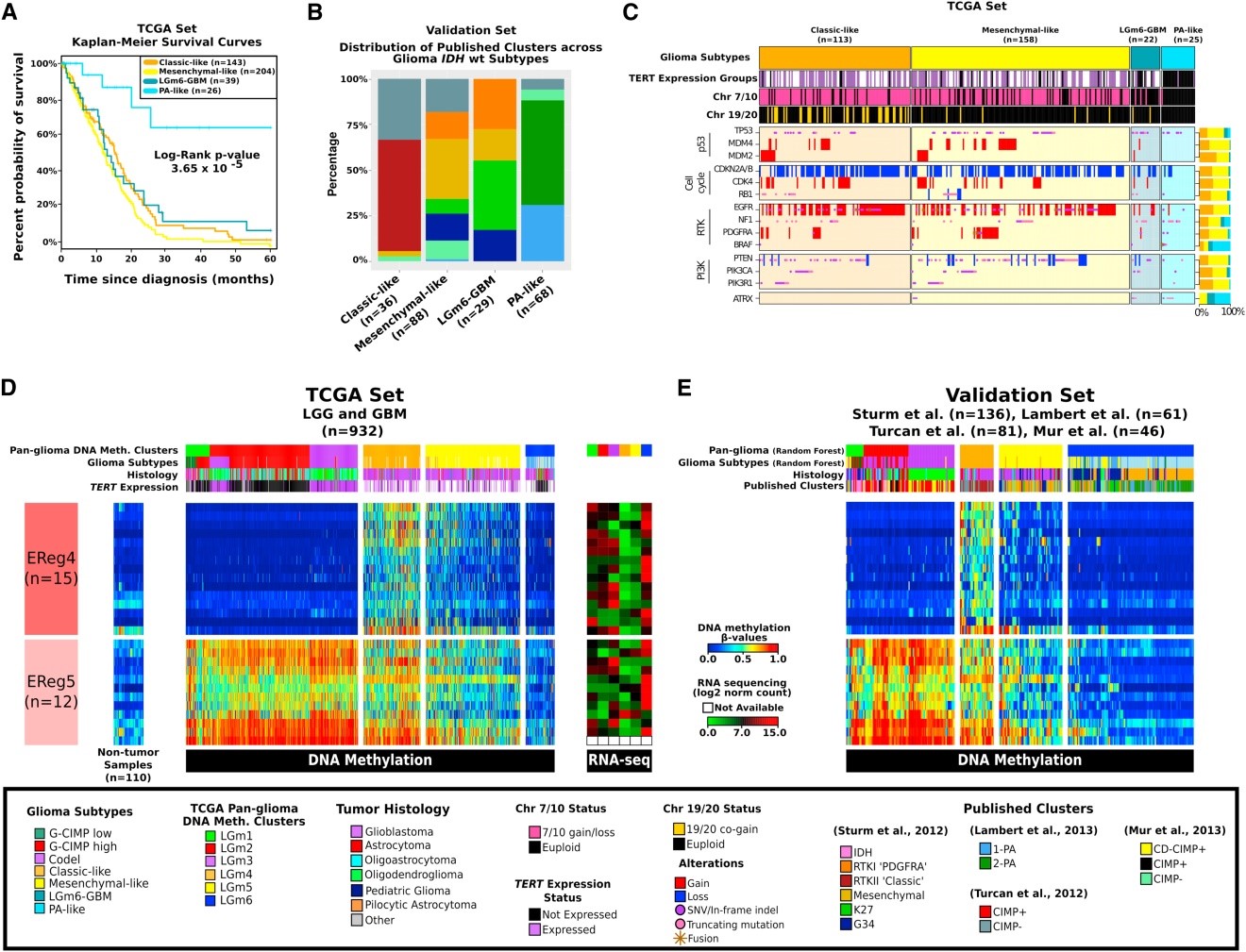
癌症研究究竟有多难?让我们来捋一下基本思路:首先,要有一定数量的高质量肿瘤临床样本;其次……等一下,是不是在“首先”这一步就卡住了?癌症研究中的高质量的肿瘤样本不但要有切除适当的肿瘤瘤体和癌旁组织,还需要每个病人的各项病理指征、家族病史、治疗手段、疗效以及对病人不间断的随访信息。要满足这些苛刻的要求,无论对于战斗在一线的临床医生,还是各大高校的科研人员都是十分困难的。难道真的没有解决办法吗?当然有!TCGA数据库,质量高、样本多,而且还是免费的!【欢脱的传送门:https://cancergenome.nih.gov/】 TCGA(The Cancer Genome Atlas),即癌症和肿瘤基因图谱计划,是由美国国家癌症和肿瘤研究所(NCI)和国家人类基因组研究所(NHGRI)联合进行的。该计划通过应用基因组分析技术,特别是采用大规模的基因组测序,将人类全部癌症(近期目标为50种包括亚型在内的肿瘤)的基因组变异图谱绘制出来,并进行系统分析,旨在找到所有致癌和抑癌基因的微小变异,了解癌细胞发生、发展的机制,在此基础上取得新的诊断和治疗方法,最后勾画出整个新型“预防癌症的策略”。我们先来看看这个数据库有多少干货: 以肝癌为例, TCGA数据库中一共包含377个肝癌样本,全部包含高质量的病理、化疗、放疗以及随访信息。其中375个样本有SNV(单核苷酸多态性和短序列插入缺失突变)变异检测结果、376个样本有表达谱(包含mRNA和miRNA)数据,376个样本有CNV(拷贝数变异)芯片数据。除此之外,还有外显子测序数据以及甲基化测序数据等等。【小编语:这个样本量!这个信息量!资深生物狗表示hin鸡冻有木有!!!】 那我们再拿出一些干货来展示如何利用TCGA数据库进行深度癌症研究AND发大牛文章。【再度欢脱的传送门:Cell. 2016 Jan 28;164(3):550-63. http://dx.doi.org/10.1016/j.cell.2015.12.028】 胶质瘤通常根据显微镜下细胞形态和一些病理特征临床分类分级,然后采取不同的治疗方法。但是传统分类法难以解释某些现象,比如某些恶性程度高的肿瘤生存期很长,而某些分级较低的肿瘤的患者则很快死亡。本文的作者采用TCGA数据库中1122个胶质瘤样本,对胶质瘤常见的driver基因进行了DNA突变、RNA表达谱以及表观修饰等不同层面的分析,从分子层面给胶质瘤的分类提供了新的思路,从而指导临床上更精细的个性化治疗。 下图展示了利用异柠檬酸脱氢酶(isocitrate dehydrogenase, IDH)的DNA甲基化数据进行聚类分析,揭示出胶质瘤可以被分为不同的六个亚型(图A);而利用RNAseq的表达量数据进行聚类,胶质瘤可以被分为四个亚群(图B)。综合两种分析方法可以从分子层面绘制清晰直观的Tumor Map(图C)。 下图展示了同样包含野生型IDH的样本在不同类型的胶质瘤中显示出不同的生存期(图A)。通过进一步分析发现,之前根据表观聚类分离出六种不同亚型在四类胶质瘤群体里分布有明显区别(图B)。一些常见的癌症Driver基因突变以及表达谱在四类胶质瘤中也有明显区别(图C)。利用之前的表观聚类,发现EReg基因(图D)以及随机验证的探针(图E)也和之前的表观聚类结果吻合的很好。 以上研究解释了为何同样包含野生型IDH的患者生存期会有极大的差别:DNA甲基化程度高的样本肿瘤发展较为缓慢,而且甲基化程度低的样本则进展极快,表现出类似其他突变型的特征,而实质上,它只是野生型突变的一个亚型。 大样本、高质量、多层面,这样的数据,无论对于肿瘤的基础研究还是临床应用来说,无疑都是莫大的福音。TCGA就是这样一个集合了以上所有闪光点的优质数据库。高性价比的套路,比如利用TCGA数据进行机制分析和挖掘+实验验证,再比如利用易获得的小样本实验+数据分析进行潜在的marker筛选+TCGA大样本验证,诸如此类等等等等任你DIY,发文章、搞产品、助攻临床,统统妥妥滴!公共数据库,就像一个待发掘的宝藏,潜心挖掘潜心分析,相信它带给我们的惊喜会越来越多。



长按加关注