pEGFP-N3荧光蛋白报告载体
产品名称: pEGFP-N3荧光蛋白报告载体
英文名称: pEGFP-N3荧光蛋白报告载体
产品编号: BiovectorPEGFPN3
产品价格: 0
产品产地: Biovector Inc. USA
品牌商标: Biovector, Addgene, ATCC, Invi
更新时间: null
使用范围: null
- 联系人 :
- 地址 : 北京市西直门外大街19号BioVector NTCC典型培养物保藏中心
- 邮编 : 100080
- 所在区域 : 北京
- 电话 : 189****8599 点击查看
- 传真 : 点击查看
- 邮箱 : Biovector@163.com
Product Data Sheet
|
Order ID |
Name |
Description |
|
BiovectorPEGFPN3 |
pEGFP-N3 |
pEGFP-N3,DNA, 15uL,KanR.Storage:-20℃ |
Transformation of plasmid DNA to competent E. Coli cells
- Thaw competent cells on ice. 20–200µL per tube
- Add max. 1-3µL of plasmid
- Mix very gently!
- Incubate the tubes on ice for 30 min
- Heat shock the cells for 45 sec to 2 min at 42°C
- Place the tubes immediately on ice for at least 2 min
- Add 800µL of SOC medium to each tube
- Incubate for 1 hour at 37°C and shake vigorously
- Spin down briefly and remove most supernatants
- Resuspend cell pellet with the rest SOC medium in the tube by pipetting
- Plate out the suspension on a LB agar plate containing the appropriate antibiotic. Incubate the plates overnight at 37°C
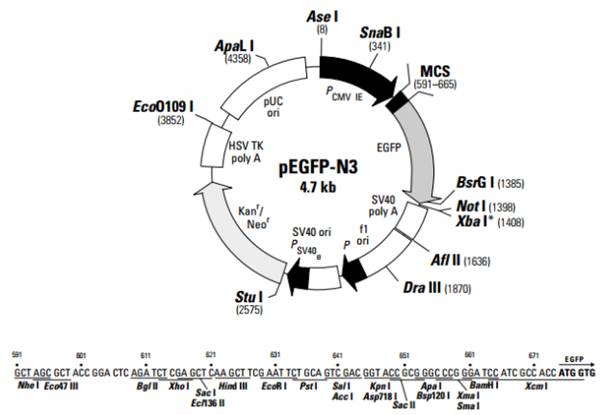
载体信息:
|
质粒类型: |
荧光蛋白报告载体 |
|
启动子: |
CMV |
|
表达水平: |
高 |
|
克隆方法: |
多克隆位点,限制性内切酶 |
|
载体大小: |
4729bp |
|
5 测序引物及序列: |
CMV-F: 5-CGCAAATGGGCGGTAGGCGTG-3 |
|
3 测序引物及序列: |
EGFP-N: 5-CGTCGCCGTCCAGCTCGACCAG-3 |
|
载体标签: |
C-EGFP |
|
载体抗性: |
Kanamycin (卡那霉素) |
|
筛选标记: |
Neomycin (新霉素) |
载体描述:
pEGFP-N3 encodes a red-shifted variant of wild-type GFP (1–3) which has been optimized for brighter fluorescence and higher expression in mammalian cells. (Excitation maximum = 488 nm; emission maximum = 507 nm.) pEGFP-N3 encodes the GFPmut1 variant (4) which contains the double-amino-acid substitution of Phe-64 to Leu and Ser-65 to Thr. The coding sequence of the EGFP gene contains more than 190 silent base changes which correspond to human codon-usage preferences (5). Sequences flanking EGFP have been converted to a Kozak consensus translation initiation site (6) to further increase the translation efficiency in eukaryotic cells. The MCS in pEGFP-N3 is between the immediate early promoter of CMV (PCMV IE) and the EGFP coding sequences. Genes cloned into the MCS will be expressed as fusions to the N terminus of EGFP if they are in the same reading frame as EGFP and there are no intervening stop codons. SV40 polyadenylation signals downstream of the EGFP gene direct proper processing of the 3 end of the EGFP mRNA. The vector backbone also contains an SV40 origin for replication in mammalian cells expressing the SV40 T-antigen. A neomycin resistance cassette (Neor), consisting of the SV40 early promoter, the neomycin/kanamycin resistance gene of Tn5, and polyadenylation signals from the Herpes simplex virus thymidine kinase (HSV TK) gene, allows stably transfected eukaryotic cells to be selected using G418. A bacterial promoter upstream of this cassette expresses kanamycin resistance in E. coli. The pEGFP-N3 backbone also provides a pUC origin of replication for propagation in E. coli and an f1 origin for single-stranded DNA production.
载体序列:
TAGTTATTAATAGTAATCAATTACGGGGTCATTAGTTCATAGCCCATATATGGAGTTCCGCGTTACATAA
CTTACGGTAAATGGCCCGCCTGGCTGACCGCCCAACGACCCCCGCCCATTGACGTCAATAATGACGTATG
TTCCCATAGTAACGCCAATAGGGACTTTCCATTGACGTCAATGGGTGGAGTATTTACGGTAAACTGCCCA
CTTGGCAGTACATCAAGTGTATCATATGCCAAGTACGCCCCCTATTGACGTCAATGACGGTAAATGGCCC
GCCTGGCATTATGCCCAGTACATGACCTTATGGGACTTTCCTACTTGGCAGTACATCTACGTATTAGTCA
TCGCTATTACCATGGTGATGCGGTTTTGGCAGTACATCAATGGGCGTGGATAGCGGTTTGACTCACGGGG
ATTTCCAAGTCTCCACCCCATTGACGTCAATGGGAGTTTGTTTTGGCACCAAAATCAACGGGACTTTCCA
AAATGTCGTAACAACTCCGCCCCATTGACGCAAATGGGCGGTAGGCGTGTACGGTGGGAGGTCTATATAA
GCAGAGCTGGTTTAGTGAACCGTCAGATCCGCTAGCGCTACCGGACTCAGATCTCGAGCTCAAGCTTCGA
ATTCTGCAGTCGACGGTACCGCGGGCCCGGGATCCATCGCCACCATGGTGAGCAAGGGCGAGGAGCTGTT
CACCGGGGTGGTGCCCATCCTGGTCGAGCTGGACGGCGACGTAAACGGCCACAAGTTCAGCGTGTCCGGC
GAGGGCGAGGGCGATGCCACCTACGGCAAGCTGACCCTGAAGTTCATCTGCACCACCGGCAAGCTGCCCG
TGCCCTGGCCCACCCTCGTGACCACCCTGACCTACGGCGTGCAGTGCTTCAGCCGCTACCCCGACCACAT
GAAGCAGCACGACTTCTTCAAGTCCGCCATGCCCGAAGGCTACGTCCAGGAGCGCACCATCTTCTTCAAG
GACGACGGCAACTACAAGACCCGCGCCGAGGTGAAGTTCGAGGGCGACACCCTGGTGAACCGCATCGAGC
TGAAGGGCATCGACTTCAAGGAGGACGGCAACATCCTGGGGCACAAGCTGGAGTACAACTACAACAGCCA
CAACGTCTATATCATGGCCGACAAGCAGAAGAACGGCATCAAGGTGAACTTCAAGATCCGCCACAACATC
GAGGACGGCAGCGTGCAGCTCGCCGACCACTACCAGCAGAACACCCCCATCGGCGACGGCCCCGTGCTGC
TGCCCGACAACCACTACCTGAGCACCCAGTCCGCCCTGAGCAAAGACCCCAACGAGAAGCGCGATCACAT
GGTCCTGCTGGAGTTCGTGACCGCCGCCGGGATCACTCTCGGCATGGACGAGCTGTACAAGTAAAGCGGC
CGCGACTCTAGATCATAATCAGCCATACCACATTTGTAGAGGTTTTACTTGCTTTAAAAAACCTCCCACA
CCTCCCCCTGAACCTGAAACATAAAATGAATGCAATTGTTGTTGTTAACTTGTTTATTGCAGCTTATAAT
GGTTACAAATAAAGCAATAGCATCACAAATTTCACAAATAAAGCATTTTTTTCACTGCATTCTAGTTGTG
GTTTGTCCAAACTCATCAATGTATCTTAAGGCGTAAATTGTAAGCGTTAATATTTTGTTAAAATTCGCGT
TAAATTTTTGTTAAATCAGCTCATTTTTTAACCAATAGGCCGAAATCGGCAAAATCCCTTATAAATCAAA
AGAATAGACCGAGATAGGGTTGAGTGTTGTTCCAGTTTGGAACAAGAGTCCACTATTAAAGAACGTGGAC
TCCAACGTCAAAGGGCGAAAAACCGTCTATCAGGGCGATGGCCCACTACGTGAACCATCACCCTAATCAA
GTTTTTTGGGGTCGAGGTGCCGTAAAGCACTAAATCGGAACCCTAAAGGGAGCCCCCGATTTAGAGCTTG
ACGGGGAAAGCCGGCGAACGTGGCGAGAAAGGAAGGGAAGAAAGCGAAAGGAGCGGGCGCTAGGGCGCTG
GCAAGTGTAGCGGTCACGCTGCGCGTAACCACCACACCCGCCGCGCTTAATGCGCCGCTACAGGGCGCGT
CAGGTGGCACTTTTCGGGGAAATGTGCGCGGAACCCCTATTTGTTTATTTTTCTAAATACATTCAAATAT
GTATCCGCTCATGAGACAATAACCCTGATAAATGCTTCAATAATATTGAAAAAGGAAGAGTCCTGAGGCG
GAAAGAACCAGCTGTGGAATGTGTGTCAGTTAGGGTGTGGAAAGTCCCCAGGCTCCCCAGCAGGCAGAAG
TATGCAAAGCATGCATCTCAATTAGTCAGCAACCAGGTGTGGAAAGTCCCCAGGCTCCCCAGCAGGCAGA
AGTATGCAAAGCATGCATCTCAATTAGTCAGCAACCATAGTCCCGCCCCTAACTCCGCCCATCCCGCCCC
TAACTCCGCCCAGTTCCGCCCATTCTCCGCCCCATGGCTGACTAATTTTTTTTATTTATGCAGAGGCCGA
GGCCGCCTCGGCCTCTGAGCTATTCCAGAAGTAGTGAGGAGGCTTTTTTGGAGGCCTAGGCTTTTGCAAA
GATCGATCAAGAGACAGGATGAGGATCGTTTCGCATGATTGAACAAGATGGATTGCACGCAGGTTCTCCG
GCCGCTTGGGTGGAGAGGCTATTCGGCTATGACTGGGCACAACAGACAATCGGCTGCTCTGATGCCGCCG
TGTTCCGGCTGTCAGCGCAGGGGCGCCCGGTTCTTTTTGTCAAGACCGACCTGTCCGGTGCCCTGAATGA
ACTGCAAGACGAGGCAGCGCGGCTATCGTGGCTGGCCACGACGGGCGTTCCTTGCGCAGCTGTGCTCGAC
GTTGTCACTGAAGCGGGAAGGGACTGGCTGCTATTGGGCGAAGTGCCGGGGCAGGATCTCCTGTCATCTC
ACCTTGCTCCTGCCGAGAAAGTATCCATCATGGCTGATGCAATGCGGCGGCTGCATACGCTTGATCCGGC
TACCTGCCCATTCGACCACCAAGCGAAACATCGCATCGAGCGAGCACGTACTCGGATGGAAGCCGGTCTT
GTCGATCAGGATGATCTGGACGAAGAGCATCAGGGGCTCGCGCCAGCCGAACTGTTCGCCAGGCTCAAGG
CGAGCATGCCCGACGGCGAGGATCTCGTCGTGACCCATGGCGATGCCTGCTTGCCGAATATCATGGTGGA
AAATGGCCGCTTTTCTGGATTCATCGACTGTGGCCGGCTGGGTGTGGCGGACCGCTATCAGGACATAGCG
TTGGCTACCCGTGATATTGCTGAAGAGCTTGGCGGCGAATGGGCTGACCGCTTCCTCGTGCTTTACGGTA
TCGCCGCTCCCGATTCGCAGCGCATCGCCTTCTATCGCCTTCTTGACGAGTTCTTCTGAGCGGGACTCTG
GGGTTCGAAATGACCGACCAAGCGACGCCCAACCTGCCATCACGAGATTTCGATTCCACCGCCGCCTTCT
ATGAAAGGTTGGGCTTCGGAATCGTTTTCCGGGACGCCGGCTGGATGATCCTCCAGCGCGGGGATCTCAT
GCTGGAGTTCTTCGCCCACCCTAGGGGGAGGCTAACTGAAACACGGAAGGAGACAATACCGGAAGGAACC
CGCGCTATGACGGCAATAAAAAGACAGAATAAAACGCACGGTGTTGGGTCGTTTGTTCATAAACGCGGGG
TTCGGTCCCAGGGCTGGCACTCTGTCGATACCCCACCGAGACCCCATTGGGGCCAATACGCCCGCGTTTC
TTCCTTTTCCCCACCCCACCCCCCAAGTTCGGGTGAAGGCCCAGGGCTCGCAGCCAACGTCGGGGCGGCA
GGCCCTGCCATAGCCTCAGGTTACTCATATATACTTTAGATTGATTTAAAACTTCATTTTTAATTTAAAA
GGATCTAGGTGAAGATCCTTTTTGATAATCTCATGACCAAAATCCCTTAACGTGAGTTTTCGTTCCACTG
AGCGTCAGACCCCGTAGAAAAGATCAAAGGATCTTCTTGAGATCCTTTTTTTCTGCGCGTAATCTGCTGC
TTGCAAACAAAAAAACCACCGCTACCAGCGGTGGTTTGTTTGCCGGATCAAGAGCTACCAACTCTTTTTC
CGAAGGTAACTGGCTTCAGCAGAGCGCAGATACCAAATACTGTCCTTCTAGTGTAGCCGTAGTTAGGCCA
CCACTTCAAGAACTCTGTAGCACCGCCTACATACCTCGCTCTGCTAATCCTGTTACCAGTGGCTGCTGCC
AGTGGCGATAAGTCGTGTCTTACCGGGTTGGACTCAAGACGATAGTTACCGGATAAGGCGCAGCGGTCGG
GCTGAACGGGGGGTTCGTGCACACAGCCCAGCTTGGAGCGAACGACCTACACCGAACTGAGATACCTACA
GCGTGAGCTATGAGAAAGCGCCACGCTTCCCGAAGGGAGAAAGGCGGACAGGTATCCGGTAAGCGGCAGG
GTCGGAACAGGAGAGCGCACGAGGGAGCTTCCAGGGGGAAACGCCTGGTATCTTTATAGTCCTGTCGGGT
TTCGCCACCTCTGACTTGAGCGTCGATTTTTGTGATGCTCGTCAGGGGGGCGGAGCCTATGGAAAAACGC
CAGCAACGCGGCCTTTTTACGGTTCCTGGCCTTTTGCTGGCCTTTTGCTCACATGTTCTTTCCTGCGTTA
TCCCCTGATTCTGTGGATAACCGTATTACCGCCATGCAT
TIMP1-bio-His TIMP1 (Homo sapiens)
TPP1-bio-His TPP1 (Homo sapiens)
TTR-bio-His TTR (Homo sapiens)
AHSG-bio-His AHSG (Homo sapiens)
ALB-bio-His ALB (Homo sapiens)
APOH-bio-His APOH (Homo sapiens)
C12-bio-His C12 (Homo sapiens)
F2-bio-His F2 (Homo sapiens)
IGFALS-bio-His IGFALS (Homo sapiens)
ITIH4-bio-His ITIH4 (Homo sapiens)
SERPINA-bio-His SERPINA (Homo sapiens)
SMR3B-bio-His SMR3B (Homo sapiens)
TF-bio-His TF (Homo sapiens)
LMAN2-bio-His LMAN2 (Homo sapiens)
M6PR-bio-His M6PR (Homo sapiens)
MET-bio-His MET (Homo sapiens)
SORT1-bio-His SORT1 (Homo sapiens)
CD36-bio-His CD36 (Homo sapiens)
ARMET-bio-His ARMET (Homo sapiens)
CCL5-bio-His CCL5 (Homo sapiens)
CTGF-bio-His CTGF (Homo sapiens)
FGA-bio-His FGA (Homo sapiens)
FGB FGB (Homo sapiens)
FGG FGG (Homo sapiens)
GGH-bio-His GGH (Homo sapiens)
GSN-bio-His GSN (Homo sapiens)
NID1-bio-His NID1 (Homo sapiens)
P4HB-bio-His P4HB (Homo sapiens)
PDIA3-bio-His PDIA3 (Homo sapiens)
PDIA4-bio-His PDIA4 (Homo sapiens)
PDIA5-bio-His PDIA5 (Homo sapiens)
PF4V1-bio-His PF4V1 (Homo sapiens)
CD109-bio-His CD109 (Homo sapiens)
F2R-bio-His F2R (Homo sapiens)
F2RL3-bio-His F2RL3 (Homo sapiens)
VIPR1 VIPR1 (Homo sapiens)
BAMBI-bio-His BAMBI (Homo sapiens)
DCBL-bio-His DCBL (Homo sapiens)
FAM-bio-His FAM (Homo sapiens)
CYYR-bio-His CYYR (Homo sapiens)
DLK1-bio-His DLK1 (Homo sapiens)
F2RL2-bio-His F2RL2 (Homo sapiens)
FCER1a-bio-His FCER1a (Homo sapiens)
LRP8-bio-His LRP8 (Homo sapiens)
GP1BA-bio-His GP1BA (Homo sapiens)
GP1BB GP1BB (Homo sapiens)
ITGA5-bio-His ITGA5 (Homo sapiens)
ITGA2-bio-His ITGA2 (Homo sapiens)
ITGAV-bio-His ITGAV (Homo sapiens)
ITGB1 ITGB1 (Homo sapiens)
ITGB3 ITGB3 (Homo sapiens)
LMAN1-bio-His LMAN1 (Homo sapiens)
PTPRJ-bio-His PTPRJ (Homo sapiens)
PTTG-bio-His PTTG (Homo sapiens)
PVRL2-bio-His PVRL2 (Homo sapiens)
QSOX1-bio-His QSOX1 (Homo sapiens)
SCARF-bio-His SCARF (Homo sapiens)
SEMA4-bio-His SEMA4 (Homo sapiens)
SPN-bio-His SPN (Homo sapiens)
STIM1-bio-His STIM1 (Homo sapiens)
TM9-bio-His TM9 (Homo sapiens)
TMED1-bio-His TMED1 (Homo sapiens)
TMED10-bio-His TMED10 (Homo sapiens)
TMED2-bio-His TMED2 (Homo sapiens)
TMED4-bio-His TMED4 (Homo sapiens)
TMED9-bio-His TMED9 (Homo sapiens)
TMEM-bio-His TMEM (Homo sapiens)
TREML1-bio-His TREML1 (Homo sapiens)
TXNDC-bio-His TXNDC (Homo sapiens)
ULBP3-bio-His ULBP3 (Homo sapiens)
PEAR1-bio-His PEAR1 (Homo sapiens)
LAMP2-bio-His LAMP2 (Homo sapiens)
CD34-bio-His CD34 (Homo sapiens)
CD40-bio-His CD40 (Homo sapiens)
CD84-bio-His CD84 (Homo sapiens)
DAG1-bio-His DAG1 (Homo sapiens)
EFNB1-bio-His EFNB1 (Homo sapiens)
EPHB1-bio-His EPHB1 (Homo sapiens)
ESAM-bio-His ESAM (Homo sapiens)
FCGR2a-bio-His FCGR2a (Homo sapiens)
FURIN-bio-His FURIN (Homo sapiens)
GP6-bio-His GP6 (Homo sapiens)
ICAM2-bio-His ICAM2 (Homo sapiens)
ICAM5-bio-His ICAM5 (Homo sapiens)
IL6ST-bio-His IL6ST (Homo sapiens)
JAM3-bio-His JAM3 (Homo sapiens)
KIAA-bio-His KIAA (Homo sapiens)
LAMP1-bio-His LAMP1 (Homo sapiens)
NRXN-bio-His NRXN (Homo sapiens)
PRNP-bio-His PRNP (Homo sapiens)
PTPRC-bio-His PTPRC (Homo sapiens)
ACVR1-b