pEGFP-Tub荧光蛋白报告载体
产品名称: pEGFP-Tub荧光蛋白报告载体
英文名称: pEGFP-Tub荧光蛋白报告载体
产品编号: BiovectorPEGFPTUB
产品价格: 0
产品产地: Biovector Inc. USA
品牌商标: Biovector, Addgene, ATCC, Invi
更新时间: null
使用范围: null
- 联系人 :
- 地址 : 北京市西直门外大街19号BioVector NTCC典型培养物保藏中心
- 邮编 : 100080
- 所在区域 : 北京
- 电话 : 189****8599 点击查看
- 传真 : 点击查看
- 邮箱 : Biovector@163.com
Product Data Sheet
|
Order ID |
Name |
Description |
|
BiovectorPEGFPTUB |
pEGFP-Tub |
pEGFP-Tub,DNA, 15uL,KanR.Storage:-20℃ |
Transformation of plasmid DNA to competent E. Coli cells
- Thaw competent cells on ice. 20–200µL per tube
- Add max. 1-3µL of plasmid
- Mix very gently!
- Incubate the tubes on ice for 30 min
- Heat shock the cells for 45 sec to 2 min at 42°C
- Place the tubes immediately on ice for at least 2 min
- Add 800µL of SOC medium to each tube
- Incubate for 1 hour at 37°C and shake vigorously
- Spin down briefly and remove most supernatants
- Resuspend cell pellet with the rest SOC medium in the tube by pipetting
- Plate out the suspension on a LB agar plate containing the appropriate antibiotic. Incubate the plates overnight at 37°C
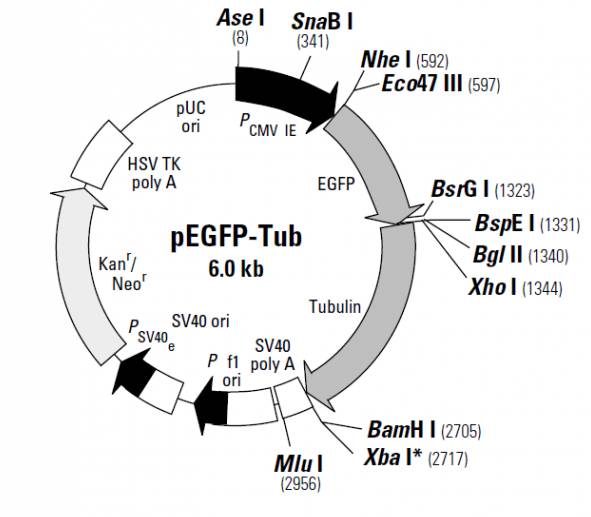
载体信息:
|
质粒类型: |
荧光蛋白报告载体 |
|
启动子: |
CMV |
|
克隆方法: |
多克隆位点,限制性内切酶 |
|
载体大小: |
6045 bp |
|
载体标签: |
EGFP |
|
载体抗性: |
Kanamycin (卡那霉素) |
|
筛选标记: |
Neomycin (新霉素) |
载体描述:
pEGFP-Tub encodes a fusion protein consisting of the red-shifted, human codon-optimized variant of green fluorescent protein (EGFP; 1–3) and the gene encoding human α-tubulin (4, 5). EGFP, a derivative of the GFPmut1 variant (6), has been optimized for brighter fluorescence and higher expression in mammalian cells. (Excitation maximum = 488 nm; emission maximum = 507 nm.) This variant contains the double-amino-acid substitution of Phe-64 to Leu and Ser-65 to Thr, as well as more than 190 silent base changes that correspond to human codon-usage preferences (7). SV40 polyadenylation signals downstream of the EGFP-Tub fusion direct proper processing of the 3 end of the mRNA. The vector backbone also contains an SV40 origin for replication in mammalian cells expressing the SV40 T-antigen. A neomycin resistance cassette (Neor), consisting of the SV40 early promoter, the neomycin/kanamycin resistance gene of Tn5, and polyadenylation signals from the herpes simplex virus thymidine kinase (HSV-TK) gene, allow stably transfected eukaryotic cells to be selected using G418. A bacterial promoter upstream of this cassette drives expression of the gene encoding kanamycin resistance in E. coli. The pEGFP-Tub backbone also provides a pUC origin of replication for propagation in E. coli and an f1 origin for single-stranded DNA production.
载体序列:
TAGTTATTAATAGTAATCAATTACGGGGTCATTAGTTCATAGCCCATATATGGAGTTCCGCGTTACATAA
CTTACGGTAAATGGCCCGCCTGGCTGACCGCCCAACGACCCCCGCCCATTGACGTCAATAATGACGTATG
TTCCCATAGTAACGCCAATAGGGACTTTCCATTGACGTCAATGGGTGGAGTATTTACGGTAAACTGCCCA
CTTGGCAGTACATCAAGTGTATCATATGCCAAGTACGCCCCCTATTGACGTCAATGACGGTAAATGGCCC
GCCTGGCATTATGCCCAGTACATGACCTTATGGGACTTTCCTACTTGGCAGTACATCTACGTATTAGTCA
TCGCTATTACCATGGTGATGCGGTTTTGGCAGTACATCAATGGGCGTGGATAGCGGTTTGACTCACGGGG
ATTTCCAAGTCTCCACCCCATTGACGTCAATGGGAGTTTGTTTTGGCACCAAAATCAACGGGACTTTCCA
AAATGTCGTAACAACTCCGCCCCATTGACGCAAATGGGCGGTAGGCGTGTACGGTGGGAGGTCTATATAA
GCAGAGCTGGTTTAGTGAACCGTCAGATCCGCTAGCGCTACCGGTCGCCACCATGGTGAGCAAGGGCGAG
GAGCTGTTCACCGGGGTGGTGCCCATCCTGGTCGAGCTGGACGGCGACGTAAACGGCCACAAGTTCAGCG
TGTCCGGCGAGGGCGAGGGCGATGCCACCTACGGCAAGCTGACCCTGAAGTTCATCTGCACCACCGGCAA
GCTGCCCGTGCCCTGGCCCACCCTCGTGACCACCCTGACCTACGGCGTGCAGTGCTTCAGCCGCTACCCC
GACCACATGAAGCAGCACGACTTCTTCAAGTCCGCCATGCCCGAAGGCTACGTCCAGGAGCGCACCATCT
TCTTCAAGGACGACGGCAACTACAAGACCCGCGCCGAGGTGAAGTTCGAGGGCGACACCCTGGTGAACCG
CATCGAGCTGAAGGGCATCGACTTCAAGGAGGACGGCAACATCCTGGGGCACAAGCTGGAGTACAACTAC
AACAGCCACAACGTCTATATCATGGCCGACAAGCAGAAGAACGGCATCAAGGTGAACTTCAAGATCCGCC
ACAACATCGAGGACGGCAGCGTGCAGCTCGCCGACCACTACCAGCAGAACACCCCCATCGGCGACGGCCC
CGTGCTGCTGCCCGACAACCACTACCTGAGCACCCAGTCCGCCCTGAGCAAAGACCCCAACGAGAAGCGC
GATCACATGGTCCTGCTGGAGTTCGTGACCGCCGCCGGGATCACTCTCGGCATGGACGAGCTGTACAAGT
CCGGACTCAGATCTCGAGTGCGTGAGTGCATCTCCATCCACGTTGGCCAGGCTGGTGTCCAGATTGGCAA
TGCCTGCTGGGAGCTCTACTGCCTGGAACACGGCATCCAGCCCGATGGCCAGATGCCAAGTGACAAGACC
ATTGGGGGAGGAGATGACTCCTTCAACACCTTCTTCAGTGAGACGGGCGCTGGCAAGCACGTGCCCCGGG
CTGTGTTTGTAGACTTGGAACCCACAGTCATTGATGAAGTTCGCACTGGCACCTACCGCCAGCTCTTCCA
CCCTGAGCAGCTCATCACAGGCAAGGAAGATGCTGCCAATAACTATGCCCGAGGGCACTACACCATTGGC
AAGGAGATCATTGACCTTGTGTTGGACCGAATTCGCAAGCTGGCTGACCAGTGCACCGGTCTTCAGGGCT
TCTTGGTTTTCCACAGCTTTGGTGGGGGAACTGGTTCTGGGTTCACCTCCCTGCTCATGGAACGTCTCTC
AGTTGATTATGGCAAGAAGTCCAAGCTGGAGTTCTCCATTTACCCAGCACCCCAGGTTTCCACAGCTGTA
GTTGAGCCCTACAACTCCATCCTCACCACCCACACCACCCTGGAGCACTCTGATTGTGCCTTCATGGTAG
ACAATGAGGCCATCTATGACATCTGTCGTAGAAACCTCGATATCGAGCGCCCAACCTACACTAACCTTAA
CCGCCTTATTAGCCAGATTGTGTCCTCCATCACTGCTTCCCTGAGATTTGATGGAGCCCTGAATGTTGAC
CTGACAGAATTCCAGACCAACCTGGTGCCCTACCCCCGCATCCACTTCCCTCTGGCCACATATGCCCCTG
TCATCTCTGCTGAGAAAGCCTACCATGAACAGCTTTCTGTAGCAGAGATCACCAATGCTTGCTTTGAGCC
AGCCAACCAGATGGTGAAATGTGACCCTCGCCATGGTAAATACATGGCTTGCTGCCTGTTGTACCGTGGT
GACGTGGTTCCCAAAGATGTCAATGCTGCCATTGCCACCATCAAAACCAAGCGCAGCATCCAGTTTGTGG
ATTGGTGCCCCACTGGCTTCAAGGTTGGCATCAACTACCAGCCTCCCACTGTGGTGCCTGGTGGAGACCT
GGCCAAGGTACAGAGAGCTGTGTGCATGCTGAGCAACACCACAGCCATTGCTGAGGCCTGGGCTCGCCTG
GACCACAAGTTTGACCTGATGTATGCCAAGCGTGCCTTTGTTCACTGGTACGTGGGTGAGGGGATGGAGG
AAGGCGAGTTTTCAGAGGCCCGTGAAGATATGGCTGCCCTTGAGAAGGATTATGAGGAGGTTGGTGTGGA
TTCTGTTGAAGGAGAGGGTGAGGAAGAAGGAGAGGAATACTAAGGATCCACCGGATCTAGATAACTGATC
ATAATCAGCCATACCACATTTGTAGAGGTTTTACTTGCTTTAAAAAACCTCCCACACCTCCCCCTGAACC
TGAAACATAAAATGAATGCAATTGTTGTTGTTAACTTGTTTATTGCAGCTTATAATGGTTACAAATAAAG
CAATAGCATCACAAATTTCACAAATAAAGCATTTTTTTCACTGCATTCTAGTTGTGGTTTGTCCAAACTC
ATCAATGTATCTTAACGCGTAAATTGTAAGCGTTAATATTTTGTTAAAATTCGCGTTAAATTTTTGTTAA
ATCAGCTCATTTTTTAACCAATAGGCCGAAATCGGCAAAATCCCTTATAAATCAAAAGAATAGACCGAGA
TAGGGTTGAGTGTTGTTCCAGTTTGGAACAAGAGTCCACTATTAAAGAACGTGGACTCCAACGTCAAAGG
GCGAAAAACCGTCTATCAGGGCGATGGCCCACTACGTGAACCATCACCCTAATCAAGTTTTTTGGGGTCG
AGGTGCCGTAAAGCACTAAATCGGAACCCTAAAGGGAGCCCCCGATTTAGAGCTTGACGGGGAAAGCCGG
CGAACGTGGCGAGAAAGGAAGGGAAGAAAGCGAAAGGAGCGGGCGCTAGGGCGCTGGCAAGTGTAGCGGT
CACGCTGCGCGTAACCACCACACCCGCCGCGCTTAATGCGCCGCTACAGGGCGCGTCAGGTGGCACTTTT
CGGGGAAATGTGCGCGGAACCCCTATTTGTTTATTTTTCTAAATACATTCAAATATGTATCCGCTCATGA
GACAATAACCCTGATAAATGCTTCAATAATATTGAAAAAGGAAGAGTCCTGAGGCGGAAAGAACCAGCTG
TGGAATGTGTGTCAGTTAGGGTGTGGAAAGTCCCCAGGCTCCCCAGCAGGCAGAAGTATGCAAAGCATGC
ATCTCAATTAGTCAGCAACCAGGTGTGGAAAGTCCCCAGGCTCCCCAGCAGGCAGAAGTATGCAAAGCAT
GCATCTCAATTAGTCAGCAACCATAGTCCCGCCCCTAACTCCGCCCATCCCGCCCCTAACTCCGCCCAGT
TCCGCCCATTCTCCGCCCCATGGCTGACTAATTTTTTTTATTTATGCAGAGGCCGAGGCCGCCTCGGCCT
CTGAGCTATTCCAGAAGTAGTGAGGAGGCTTTTTTGGAGGCCTAGGCTTTTGCAAAGATCGATCAAGAGA
CAGGATGAGGATCGTTTCGCATGATTGAACAAGATGGATTGCACGCAGGTTCTCCGGCCGCTTGGGTGGA
GAGGCTATTCGGCTATGACTGGGCACAACAGACAATCGGCTGCTCTGATGCCGCCGTGTTCCGGCTGTCA
GCGCAGGGGCGCCCGGTTCTTTTTGTCAAGACCGACCTGTCCGGTGCCCTGAATGAACTGCAAGACGAGG
CAGCGCGGCTATCGTGGCTGGCCACGACGGGCGTTCCTTGCGCAGCTGTGCTCGACGTTGTCACTGAAGC
GGGAAGGGACTGGCTGCTATTGGGCGAAGTGCCGGGGCAGGATCTCCTGTCATCTCACCTTGCTCCTGCC
GAGAAAGTATCCATCATGGCTGATGCAATGCGGCGGCTGCATACGCTTGATCCGGCTACCTGCCCATTCG
ACCACCAAGCGAAACATCGCATCGAGCGAGCACGTACTCGGATGGAAGCCGGTCTTGTCGATCAGGATGA
TCTGGACGAAGAGCATCAGGGGCTCGCGCCAGCCGAACTGTTCGCCAGGCTCAAGGCGAGCATGCCCGAC
GGCGAGGATCTCGTCGTGACCCATGGCGATGCCTGCTTGCCGAATATCATGGTGGAAAATGGCCGCTTTT
CTGGATTCATCGACTGTGGCCGGCTGGGTGTGGCGGACCGCTATCAGGACATAGCGTTGGCTACCCGTGA
TATTGCTGAAGAGCTTGGCGGCGAATGGGCTGACCGCTTCCTCGTGCTTTACGGTATCGCCGCTCCCGAT
TCGCAGCGCATCGCCTTCTATCGCCTTCTTGACGAGTTCTTCTGAGCGGGACTCTGGGGTTCGAAATGAC
CGACCAAGCGACGCCCAACCTGCCATCACGAGATTTCGATTCCACCGCCGCCTTCTATGAAAGGTTGGGC
TTCGGAATCGTTTTCCGGGACGCCGGCTGGATGATCCTCCAGCGCGGGGATCTCATGCTGGAGTTCTTCG
CCCACCCTAGGGGGAGGCTAACTGAAACACGGAAGGAGACAATACCGGAAGGAACCCGCGCTATGACGGC
AATAAAAAGACAGAATAAAACGCACGGTGTTGGGTCGTTTGTTCATAAACGCGGGGTTCGGTCCCAGGGC
TGGCACTCTGTCGATACCCCACCGAGACCCCATTGGGGCCAATACGCCCGCGTTTCTTCCTTTTCCCCAC
CCCACCCCCCAAGTTCGGGTGAAGGCCCAGGGCTCGCAGCCAACGTCGGGGCGGCAGGCCCTGCCATAGC
CTCAGGTTACTCATATATACTTTAGATTGATTTAAAACTTCATTTTTAATTTAAAAGGATCTAGGTGAAG
ATCCTTTTTGATAATCTCATGACCAAAATCCCTTAACGTGAGTTTTCGTTCCACTGAGCGTCAGACCCCG
TAGAAAAGATCAAAGGATCTTCTTGAGATCCTTTTTTTCTGCGCGTAATCTGCTGCTTGCAAACAAAAAA
ACCACCGCTACCAGCGGTGGTTTGTTTGCCGGATCAAGAGCTACCAACTCTTTTTCCGAAGGTAACTGGC
TTCAGCAGAGCGCAGATACCAAATACTGTCCTTCTAGTGTAGCCGTAGTTAGGCCACCACTTCAAGAACT
CTGTAGCACCGCCTACATACCTCGCTCTGCTAATCCTGTTACCAGTGGCTGCTGCCAGTGGCGATAAGTC
GTGTCTTACCGGGTTGGACTCAAGACGATAGTTACCGGATAAGGCGCAGCGGTCGGGCTGAACGGGGGGT
TCGTGCACACAGCCCAGCTTGGAGCGAACGACCTACACCGAACTGAGATACCTACAGCGTGAGCTATGAG
AAAGCGCCACGCTTCCCGAAGGGAGAAAGGCGGACAGGTATCCGGTAAGCGGCAGGGTCGGAACAGGAGA
GCGCACGAGGGAGCTTCCAGGGGGAAACGCCTGGTATCTTTATAGTCCTGTCGGGTTTCGCCACCTCTGA
CTTGAGCGTCGATTTTTGTGATGCTCGTCAGGGGGGCGGAGCCTATGGAAAAACGCCAGCAACGCGGCCT
TTTTACGGTTCCTGGCCTTTTGCTGGCCTTTTGCTCACATGTTCTTTCCTGCGTTATCCCCTGATTCTGT
GGATAACCGTATTACCGCCATGCAT
TIMP1-bio-His TIMP1 (Homo sapiens)
TPP1-bio-His TPP1 (Homo sapiens)
TTR-bio-His TTR (Homo sapiens)
AHSG-bio-His AHSG (Homo sapiens)
ALB-bio-His ALB (Homo sapiens)
APOH-bio-His APOH (Homo sapiens)
C12-bio-His C12 (Homo sapiens)
F2-bio-His F2 (Homo sapiens)
IGFALS-bio-His IGFALS (Homo sapiens)
ITIH4-bio-His ITIH4 (Homo sapiens)
SERPINA-bio-His SERPINA (Homo sapiens)
SMR3B-bio-His SMR3B (Homo sapiens)
TF-bio-His TF (Homo sapiens)
LMAN2-bio-His LMAN2 (Homo sapiens)
M6PR-bio-His M6PR (Homo sapiens)
MET-bio-His MET (Homo sapiens)
SORT1-bio-His SORT1 (Homo sapiens)
CD36-bio-His CD36 (Homo sapiens)
ARMET-bio-His ARMET (Homo sapiens)
CCL5-bio-His CCL5 (Homo sapiens)
CTGF-bio-His CTGF (Homo sapiens)
FGA-bio-His FGA (Homo sapiens)
FGB FGB (Homo sapiens)
FGG FGG (Homo sapiens)
GGH-bio-His GGH (Homo sapiens)
GSN-bio-His GSN (Homo sapiens)
NID1-bio-His NID1 (Homo sapiens)
P4HB-bio-His P4HB (Homo sapiens)
PDIA3-bio-His PDIA3 (Homo sapiens)
PDIA4-bio-H